卡顿优化
在我们使用各种各样的App的时候,有时会看见有些App运行起来并不流畅,即出现了卡顿现象,那么如何去定义发生了卡顿现象呢?
1 | 如果App的FPS平均值小于30,最小值小于24,即表明应用发生了卡顿。 |
那我么又如何去分析应用是否出现了卡顿呢?下面,我们就先来了解一下解决卡顿问题时需要用到的分析方法与工具。
一、卡顿优化分析方法与工具
1、背景介绍
- 很多性能问题不易被发现,但是卡顿问题很容易被直观感受。
- 卡顿问题难以定位。
那么卡顿问题到底难在哪里呢?
- 1、卡顿产生的原因是错综复杂的,它涉及到代码、内存、绘制、IO、CPU等等。
- 2、线上的卡顿问题在线下是很难复现的,因为它与当时的场景是强相关的,比如说线上用户的磁盘IO空间不足了,它影响了磁盘IO的写入性能,所以导致卡顿。针对这种问题,我们最好在发现卡顿的时候尽量地去记录用户当时发生卡顿时的具体的场景信息。
2、卡顿分析方法之使用shell命令分析CPU耗时
尽管造成卡顿的原因有很多种,不过最终都会反映到CPU时间上。
CPU时间包含用户时间和系统时间。
- 用户时间:执行用户态应用程序代码所消耗的时间。
- 系统时间:执行内核态系统调用所消耗的时间,包括I/O、锁、中断和其它系统调用所消耗的时间。
CPU的问题大致可以分为以下三类:
1、CPU资源冗余使用
- 算法效率太低:明明可以遍历一次的却需要去遍历两次,主要出现在查找、排序、删除等环节。
- 没有使用cache:明明解码过一次的图片还去重复解码。
- 计算时使用的基本类型不对:明明使用int就足够,却要使用long,这会导致CPU的运算压力多出4倍。
2、CPU资源争抢
- 抢主线程的CPU资源:这是最常见的问题,并且在Android 6.0版本之前没有renderthread的时候,主线程的繁忙程度就决定了是否会引发用户的卡顿问题。
- 抢音视频的CPU资源:音视频编解码本身会消耗大量的CPU资源,并且其对于解码的速度是有硬性要求的,如果达不到就可能产生播放流畅度的问题。我们可以采取两种方式去优化:1、尽量排除非核心业务的消耗。2、优化自身的性能消耗,把CPU负载转化为GPU负载,如使用renderscript来处理视频中的影像信息。
- 大家平等,互相抢:比如在自定义的相册中,我开了20个线程做图片解码,那就是互相抢CPU了,结果就是会导致图片的显示速度非常慢。这简直就是三个和尚没水喝的典型案例。因此,在自定义线程池的时候我们需要按照系统核心数去控制线程数。
3、CPU资源利用率低
对于启动、界面切换、音视频编解码这些场景,为了保证其速度,我们需要去好好利用CPU。而导致无法充分利用CPU的因素,不仅有磁盘和网络I/O,还有锁操作、sleep等等。对于锁的优化,通常是尽可能地缩减锁的范围。
1、了解CPU 性能
我们可以通过CPU的主频、核心数、缓存等参数去评估CPU的性能,这些参数的好坏能表现出CPU计算能力和指令执行能力的强弱,也就是CPU每秒执行的浮点计算数和每秒执行的指令数的多少。
此外,现在最新的主流机型都使用了多级能效的CPU架构(即多核分层架构),以确保在平常低负荷工作时能仅使用低频核心来节省电量。
并且,我们还可以通过shell命令直接查看手机的CPU核心数与频率等信息,如下所示:
1 | // 先输入adb shell进入手机的shell环境 |
从 CPU 到 GPU 再到 AI 芯片(如专为神经网络计算打造的 NPU(Neural network Processing Unit)),随着手机 CPU 整体性能的飞跃,医疗诊断、图像超清化等一些 AI 应用场景也可以在移动端更好地落地。我们可以充分利用移动端的计算能力来降低高昂的服务器成本。
此外,CPU的性能越好,应用就能获得更好的支持,如线程池可以根据不同手机的CPU核心数来配备不同的线程数、仅在手机主频比较高或者带有NPU的设备去开启一些高级的AI功能。
2、通过读取/proc/stat与/proc/[PID]/stat文件来计算并评估系统的CPU耗时情况
当应用出现卡顿问题之后,首先我们应该查看系统CPU的使用率。
首先,我们通过读取 /proc/stat 文件获取总的 CPU 时间,并读取 /proc/[PID]/stat 获取应用进程 的CPU 时间,然后,采样两个足够短的时间间隔的 CPU 快照与进程快照来计算其 CPU 使用率。
计算总的 CPU 使用率
1、采样两个足够短的时间间隔的 CPU 快照,即需要前后两次去读取 /proc/stat 文件,获取两个时间点对应的数据,如下所示:
1 | // 第一次采样 |
因为我的手机是8核,所以这里的cpu个数是8个,从cpu0到cpu7,第一行的cpu即是8个cpu的指标数据汇总,因为是要计算系统cpu的使用率,那当然应该以cpu为基准了。两次采样的CPU指标数据如下:
1 | cpu1 9931551 1082101 9002534 174463041 340947 1060438 1088978 0 0 0 |
其对应的各项指标如下:
1 | CPU (user, nice, system, idle, iowait, irq, softirq, stealstolen, guest); |
拿cpu1(9931551 1082101 9002534 174463041 340947 1060438 1088978 0 0 0)的数据来说,下面,我就来详细地解释下这些指标的含义。
- user(9931551): 表示从系统启动开始至今处于用户态的运行时间,注意不包含 nice 值为负的进程。
- nice(1082101) :表示从系统启动开始至今nice 值为负的进程所占用的 CPU 时间。
- system(9002534): 表示从系统启动开始至今处于内核态的运行时间。
- idle(174463041) :表示从系统启动开始至今除 IO 等待时间以外的其他等待时间。
- iowait(340947):表示从系统启动开始至今的IO 等待时间。(从Linux V2.5.41开始包含)
- irq(1060438):表示从系统启动开始至今的硬中断时间。(从Linux V2.6.0-test4开始包含)
- softirq(1088978):表示从系统启动开始至今的软中断时间。(从Linux V2.6.0-test4开始包含)
- stealstolen(0) :表示当在虚拟化环境中运行时在其他操作系统中所花费的时间。在Android系统下此值为0。(从Linux V2.6.11开始包含)
- guest(0) :表示当在Linux内核的控制下为其它操作系统运行虚拟CPU所花费的时间。在Android系统下此值为0。(从 V2.6.24开始包含)
此外,这些数值的单位都是 jiffies,jiffies 是内核中的一个全局变量,用来记录系统启动以来产生的节拍数,在 Linux 中,一个节拍大致可以理解为操作系统进程调度的最小时间片,不同的 Linux 系统内核中的这个值可能不同,通常在 1ms 到 10ms 之间。
了解了/proc/stat命令下各项参数的含义之后,我们就可以由前后两次时间点的CPU数据计算得到cpu1与cpu2的活动时间,如下所示:
1 | totalCPUTime = user + nice + system + idle + iowait + irq + softirq + stealstolen + guest |
因此可得出总的CPU时间,如下所示:
1 | totalCPUTime = CPU2 – CPU1 = 3830jiffies |
最后,我们就可以计算出系统CPU的使用率::
1 | // 先计算得到CPU的空闲时间 |
可以看到,前后两次时间点间的CPU使用率大概为8%,说明我们系统的CPU是处于空闲状态的,如果CPU 使用率一直大于 60% ,则表示系统处于繁忙状态,此时就需要进一步分析用户时间和系统时间的比例,看看到底是系统占用了CPU还是应用进程占用了CPU。
3、使用top命令查看应用进程的CPU消耗情况
此外,由于Android是基于Linux内核改造而成的操作系统,自然而然也能使用Linux的一些常用命令。比如我们可以使用top命令查看哪些进程是 CPU 的主要消耗者。
1 | // 直接使用top命令会定时不断地输出进程的相关信息 |
从以上可知我们的Awesome-WanAndroid应用进程占用了15.6%的CPU。最后,这里再列举下最常用的top命令,如下所示:
1 | // 排除0%的进程信息 |
4、PS软件
除了top命令可以比较全面地查看整体的CPU信息之外,如果我们只想查看当前指定进程已经消耗的CPU时间占系统总时间的百分比或其它的状态信息的话,可以使用ps命令,常用的ps命令如下所示:
1 | // 查看指定进程的状态信息 |
其中输出参数的含义如下所示:
- USER:用户名
- PID:进程ID
- PPID:父进程ID
- VSZ:虚拟内存大小(1k为单位)
- RSS:常驻内存大小(正在使用的页)
- WCHAN:进程在内核态中的运行时间
- Instruction pointer:指令指针
- NAME:进程名字
最后的输出参数S表示的是进程当前的状态,总共有10种可能的状态,如下所示:
1 | R (running) S (sleeping) D (device I/O) T (stopped) t (traced) |
可以看到,我们当前主进程是休眠的状态。
5、dumpsys cpuinfo
使用dumpsys cpuinfo命令获得的信息比起top命令得到的信息要更加精炼,如下所示:
1 | platina:/ $ dumpsys cpuinfo |
从上述信息可知,第一行显示的是cpuload (负载平均值)信息:Load: 1.92 / 1.59 / 0.97 这三个数字表示逐渐变长的时间段(平均一分钟,五分钟和十五分钟)的平均值,而较低的数字则更好。数字越大表示有问题或机器过载。需要注意的是,这里的Load需要除以核心数,比如我这里的系统核心数为8核,所以最终每一个单核CPU的Load为0.24 / 0.20 / 0.12,如果Load超过1,则表示出现了问题。
此外,占用系统CPU资源最高的是system_server进程,而我们的wanandroid应用进程仅占用了 1.4%的CPU资源,其中有0.9%的是用户态所占用的时间,0.4%是内核态所占用的时间。最后,我们可以看到系统总占用的CPU时间是13%,这个值是根据前面所有值加起来 / 系统CPU数的处理的,也就是**104% / 8 = 13%**。
除了上述方式来分析系统与应用的CPU使用情况之外,我们还应该关注卡顿率与卡顿树这两个指标。它们能帮助我们有效地去评估、并且更有针对性地去优化应用发生的卡顿。
卡顿率
类似于深入探索Android稳定性优化一文中讲到的UV、PV崩溃率,卡顿也可以有其对应的UV、PV卡顿率,UV就是Unique visitor,指的就是一台手机客户端为一个访客,00:00-24:00内相同的客户端只被计算一次。而PV即Page View,即页面浏览量或点击量。所以UV、PV卡顿率的定义即为如下所示:
1 | // UV 卡顿率可以评估卡顿的影响范围 |
因为卡顿问题的采样规则跟内存问题是相似的,一般都是采取抽样上报的方式,并且都应该按照单个用户来抽样。一个用户如果命中采集,那么在一天内都会持续的采集数据。
卡顿树
我们可以实现卡顿的火焰图,即卡顿树,在一张图里就可以看到卡顿的整体信息。由于卡顿的具体耗时跟手机性能,还有当时的使用场景、环境等密切相关,而且卡顿问题在日活大的应用上出现的场景非常多,所以对于大于我们指定的卡顿阈值如1s\2s\3s时,我们就可以抛弃具体的耗时,只按照相同堆栈出现的比例来聚合各类卡顿信息。这样我们就能够很直观地从卡顿树上看到到底哪些堆栈出现的卡顿问题最多,以便于我们能够优先去解决 Top 的卡顿问题,达到使用最少的精力获取最大的优化效果的目的。
3、卡顿优化工具
1、CPU Profiler回顾
CPU Profiler的使用笔者已经在深入探索Android启动速度优化中详细分析过了,如果对CPU Profiler还不是很熟悉的话,可以去看看这篇文章。
下面我们来简单来回顾一下CPU Profiler。
优势:
- 图形的形式展示执行时间、调用栈等。
- 信息全面,包含所有线程。
劣势:
运行时开销严重,整体都会变慢,可能会带偏我们的优化方向。
使用方式:
1 | Debug.startMethodTracing(""); |
最终生成的生成文件在sd卡:Android/data/packagename/files。
2、Systrace回顾
systrace 利用了 Linux 的ftrace调试工具(ftrace是用于了解Linux内核内部运行情况的调试工具),相当于在系统各个关键位置都添加了一些性能探针,也就是在代码里加了一些性能监控的埋点。Android 在 ftrace 的基础上封装了atrace,并增加了更多特有的探针,比如Graphics、Activity Manager、Dalvik VM、System Server 等等。对于Systrace的使用笔者在深入探索Android启动速度优化这篇文章中已经详细分析过了,如果对Systrace还不是很熟悉的话可以去看看这篇文章。
下面我们来简单回顾一下Systrace。
作用:
监控和跟踪API调用、线程运行情况,生成HTML报告。
建议:
API 18以上使用,推荐使用TraceCompat。
使用方式:
使用python命令执行脚本,后面加上一系列参数,如下所示:
1 | python systrace.py -t 10 [other-options] [categories] |
具体参数含义如下:
- -t:指定统计时间为20s。
- shced:cpu调度信息。
- gfx:图形信息。
- view:视图。
- wm:窗口管理。
- am:活动管理。
- app:应用信息。
- webview:webview信息。
- -a:指定目标应用程序的包名。
- -o:生成的systrace.html文件。
优势:
- 1、轻量级,开销小。
- 2、它能够直观地反映CPU的利用率。
- 3、右侧的Alerts能够根据我们应用的问题给出具体的建议,比如说,它会告诉我们App界面的绘制比较慢或者GC比较频繁。
最后,我们还可以通过编译时给每个函数插桩的方式来实现线下自动增加应用程序的耗时分析,但是要注意需过滤大部分的短函数,以减少性能损耗(这一点可以通过黑名单配置的方式去过滤短函数或调用非常频繁的函数)。使用这种方式我们就可以看到整个应用程序的调用流程。包括应用关键线程的函数调用,例如渲染耗时、线程锁,GC 耗时等等。这里可以使用zhengcx的MethodTraceMan,但是目前仅仅能实现对包名和类名的过滤配置,所以需要对源码进行定制化,以支持过滤短函数或调用非常频繁函数的配置功能。
基于性能的考虑,如果要在线上使用此方案,最好只去监控主线程的耗时。虽然插桩方案对性能的影响并不是很大,但是建议仅在线下或灰度环境中使用。
此外,如果你需要分析Native 函数的调用,请使用Android 5.0 新增的Simpleperf性能分析工具,它利用了 CPU 的性能监控单元(PMU)提供的硬件 perf 事件。使用 Simpleperf 可以看到所有的 Native 代码的耗时,对一些 Android 系统库的调用,在分析问题时有比较大的帮助,例如分析加载 dex、verify class 的耗时等等。此外,在 Android Studio 3.2 中的 Profiler 也直接支持了 Simpleper(SampleNative性能分析工具 (API Level 26+)),这更加方便了native代码的调试。
3、StrictMode
StrictMode是Android 2.3引入的一个工具类,它被称为严苛模式,是Android提供的一种运行时检测机制,可以用来帮助开发人员用来检测代码中一些不规范的问题。对于我们的项目当中,可能会成千上万行代码,如果我们用肉眼Review,这样不仅效率非常低效,而且比较容易出问题。使用StrictMode之后,系统会自动检测出来在主线程中的一些异常情况,并按照我们的配置给出相应的反应。
StrictMode这个工具是非常强大的,但是我们可能因为对它不熟悉而忽略掉它。StrictMode主要用来检测两大问题:
1、线程策略
线程策略的检测内容,是一些自定义的耗时调用、磁盘读取操作以及网络请求等。
2、虚拟机策略
虚拟机策略的检测内容如下:
- Activity泄漏
- Sqlite对象泄漏
- 检测实例数量
StrictMode实战
如果要在应用中使用StrictMode,只需要在Applicaitoin的onCreate方法中对StrictMode进行统一配置,代码如下所示:
1 | private void initStrictMode() { |
最后,在日志输出栏中注意使用“StrictMode”关键字过滤出对应的log即可。
4、Profilo
Profilo是一个用于收集应用程序生产版本的性能跟踪的Android库。
对于Profilo来说,它集成了atrace功能,ftrace 所有的性能埋点数据都会通过 trace_marker 文件写入到内核缓冲区,Profilo 使用了 PLT Hook 拦截了写入操作,以选择部分关心的事件去做特定的分析。这样所有的 systrace 的探针我们都可以拿到,例如四大组件生命周期、锁等待时间、类校验、GC 时间等等。不过大部分的 atrace 事件都比较笼统,从事件“B|pid|activityStart”,我们无法明确知道该事件具体是由哪个 Activity 来创建的。
此外,使用Profilo还能够快速获取Java堆栈。由于获取堆栈需要暂停主线程的运行,所以profilo通过间隔发送 SIGPROF 信号这样一种类似 Native 崩溃捕捉的方式去快速获取 Java 堆栈。
Profilo能够低耗时地快速获取Java堆栈的具体实现原理为当Signal Handler 捕获到信号后,它就会获取到当前正在执行的 Thread,通过 Thread 对象就可以拿到当前线程的 ManagedStack,ManagedStack 是一个单链表,它保存了当前的 ShadowFrame 或者 QuickFrame 栈指针,先依次遍历 ManagedStack 链表,然后遍历其内部的 ShadowFrame 或者 QuickFrame 还原一个可读的调用栈,从而 unwind 出当前的 Java 堆栈。关于ManagedStack与ShadowFrame、QuickFrame三者的关系如下图所示:
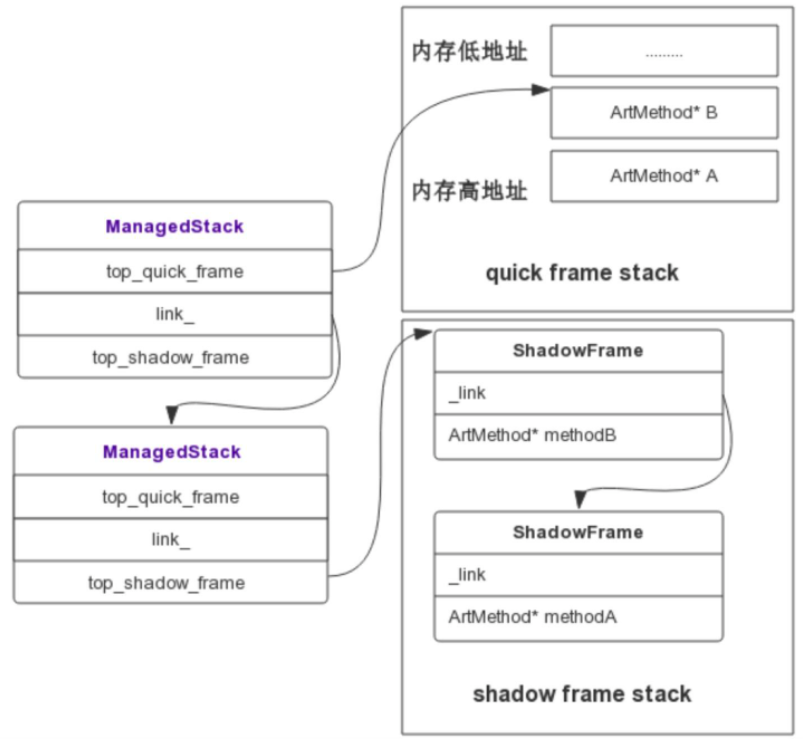
Profilo通过这种方式,就可以实现线程同步运行的同时,我们还可以去帮它做检查,并且耗时基本可以忽略不计。但是目前 Profilo 快速获取堆栈的功能不支持 Android 8.0 和 Android 9.0,并且它内部使用了Hook等大量的黑科技手段,鉴于稳定性问题,建议采取抽样部分用户的方式来开启该功能。
前面我们说过,Profilo最终也使用了ftrace,而Systrace主要也是根据Linux的ftrace机制来实现的,而ftrace的作用是帮助我们了解 Linux 内核的运行时行为,以便进行故障调试或性能分析。ftrace的整体架构如下所示:
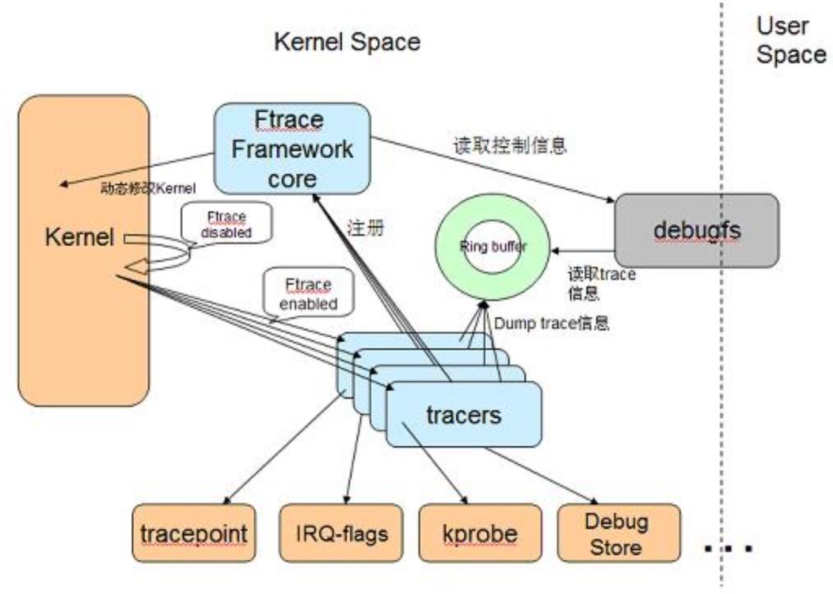
由上图可知,Ftrace 有两大组成部分,一个是 framework,另外就是一系列的 tracer 。每个 tracer 用于完成不同的功能,并且它们统一由 framework 管理。 ftrace 的 trace 信息保存在 ring buffer 中,由 framework 负责管理。 Framework 利用 debugfs 系统在 /debugfs 下建立 tracing 目录,并提供了一系列的控制文件。
下面,我这里给出使用 PLTHook 技术来获取 Atrace 日志的一个项目。
1、使用profilo的PLTHook来hook libc.so的 write 与 __write_chk 方法
使用 PLTHook 技术来获取 Atrace 的日志-项目地址
运行项目后,我们点击按钮开启Atrace日志,然后就可以在Logcat中看到如下的native层日志信息:
1 | 2020-02-05 10:58:00.873 13052-13052/com.dodola.atrace I/HOOOOOOOOK: ===============install systrace hoook================== |
需要注意的是,日志中的B代表begin,也就是对应时间开始的时间,而E代表End,即对应事件结束的时间,并且,B|事件和E|事件是成对出现的,这样我们就可以通过该事件的结束时间减去对应的开始时间来获得每个事件使用的时间。例如,上述log中我们可以看出TextView的draw方法显示使用了3ms。
此外,在下面这个项目里展示了如何使用 PLTHook 技术来获取线程创建的堆栈。
2、使用PLTHook技术来获取线程创建的堆栈
运行项目后,我们点击开启 Thread Hook按钮,然后点击新建 Thread按钮。最后可以在Logcat 中看到Thread创建的堆栈信息:
1 | 2020-02-05 13:47:59.006 20159-20159/com.dodola.thread E/HOOOOOOOOK: stack:com.dodola.thread.ThreadHook.getStack(ThreadHook.java:16) |
由于Profilo与PLT Hook涉及了大量的C/C++、NDK开发的知识,限于篇幅,所以这部分不做详细讲解,如对NDK开发感兴趣的同学可以期待下我后面的Awesome-Android-NDK系列文章,等性能优化系列文章更新完毕之后,就会开始去系统地学习NDK相关的开发知识,敬请期待。
二、自动化卡顿检测方案及优化
1、为什么需要自动化卡顿检测方案?
主要有以下两点原因:
- 1、Cpu Profiler、Systrace等系统工具仅适合线下针对性分析。
- 2、线上及测试环境需要自动化的卡顿检方案来定位卡顿,同时,更重要的是,它能记录卡顿发生时的场景。
2、卡顿检测方案原理
它的原理源于Android的消息处理机制,一个线程不管有多少Handler,它只会有一个Looper存在,主线程执行的任何代码都会通过Looper.loop()方法执行。而在Looper函数中,它有一个mLogging对象,这个对象在每个message处理前后都会被调用。主线程发生了卡顿,那一定是在dispatchMessage()方法中执行了耗时操作。那么,我们就可以通过这个mLogging对象对dispatchMessage()进行监控。
卡顿检测方案的具体实现步骤
首先,我们看下Looper用于执行消息循环的loop()方法,关键代码如下所示:
1 | /** |
在Looper的loop()方法中,在其执行每一个消息(注释2处)的前后都由logging进行了一次打印输出。可以看到,在执行消息前是输出的”>>>>> Dispatching to “,在执行消息后是输出的”<<<<< Finished to “,它们打印的日志是不一样的,我们就可以由此来判断消息执行的前后时间点。
所以,具体的实现可以归纳为如下步骤:
- 1、首先,我们需要使用Looper.getMainLooper().setMessageLogging()去设置我们自己的Printer实现类去打印输出logging。这样,在每个message执行的之前和之后都会调用我们设置的这个Printer实现类。
- 2、如果我们匹配到”>>>>> Dispatching to “之后,我们就可以执行一行代码:也就是在指定的时间阈值之后,我们在子线程去执行一个任务,这个任务就是去获取当前主线程的堆栈信息以及当前的一些场景信息,比如:内存大小、电脑、网络状态等。
- 3、如果在指定的阈值之内匹配到了”<<<<< Finished to “,那么说明message就被执行完成了,则表明此时没有产生我们认为的卡顿效果,那我们就可以将这个子线程任务取消掉。
3、AndroidPerformanceMonitor
它是一个非侵入式的性能监控组件,可以通过通知的形式弹出卡顿信息。它的原理就是我们刚刚讲述到的卡顿监控的实现原理。
接下我们通过一个简单的示例来讲解一下它的使用。
首先,我们需要在moudle的build.gradle下配置它的依赖,如下所示:
1 | // release:项目中实现了线上监控体系的时候去使用 |
其次,在Application的onCreate方法中开启卡顿监控:
1 | // 注意在主进程初始化调用 |
最后,继承BlockCanaryContext类去实现自己的监控配置上下文类:
1 | public class AppBlockCanaryContext extends BlockCanaryContext { |
可以看到,在上述配置中,我们指定了卡顿的阈值为1000ms。接下来,我们可以测试一下BlockCanary监测卡顿时的效果,这里我在Activity的onCreate方法中添加如下代码使线程休眠3s:
1 | try { |
然后,我们运行项目,打开App,即可看到类似LeakCanary界面那样的卡顿信息堆栈。
除了发生卡顿时BlockCanary提供的图形界面可供开发和测试人员直接查看卡顿原因之外。其最大的作用还是在线上环境或者自动化monkey测试的环节进行大范围的log采集与分析,对于分析的纬度,可以从以下两个纬度来进行:
- 卡顿时间。
- 根据同堆栈出现的卡顿次数来进行排序和归类。
BlockCanary的优势如下
- 非侵入式。
- 方便精准,能够定位到代码的某一行代码。
那么这种自动检测卡顿的方案有什么问题吗?
在卡顿的周期之内,应用确实发生了卡顿,但是获取到的卡顿信息可能会不准确,和我们的OOM一样,也就是最后的堆栈信息仅仅只是一个表象,并不是真正发生问题时的一个堆栈。下面,我们先看下如下的一个示意图:
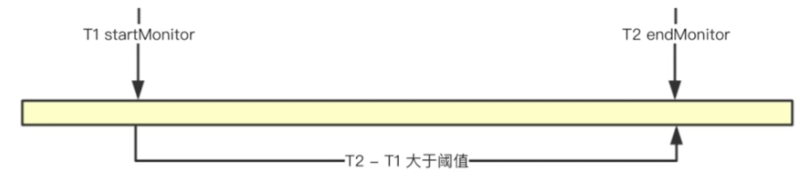
假设主线程在T1到T2的时间段内发生了卡顿,卡顿检测方案获取卡顿时的堆栈信息是T2时刻,但是实际上发生卡顿的时刻可能是在这段时间区域内另一个耗时过长的函数,那么可能在我们捕获卡顿的时刻时,真正的卡顿时机已经执行完成了,所以在T2时刻捕获到的一个卡顿信息并不能够反映卡顿的现场,也就是最后呈现出来的堆栈信息仅仅只是一个表象,并不是真正问题的藏身之处。
那么,我们如何对这种情况进行优化呢?
我们可以获取卡顿周期内的多个堆栈,而不仅仅是最后一个,这样的话,如果发生了卡顿,我们就可以根据这些堆栈信息来清晰地还原整个卡顿现场。因为我们有卡顿现场的多个堆栈信息,我们完全知道卡顿时究竟发生了什么,到底哪些函数它的调用时间比较长。接下来,我们看看下面的卡顿检测优化流程图:

根据图中,可以梳理出优化后的具体实现步骤为:
- 1、首先,我们会通过startMonitor方法对这个过程进行监控。
- 2、接着,我们就开始高频采集堆栈信息。如果发生了卡顿,我们就会调用endMonitor方法。
- 3、然后,将之前我们采集的多个堆栈信息记录到文件中。
- 4、最后,在合适的时机上报给我们的服务器。
通过上述的优化,我们就可以知道在整个卡顿周期之内,究竟是哪些方法在执行,哪些方法比较耗时。
但是这种海量卡顿堆栈的处理又存在着另一个问题,那就是高频卡顿上报量太大,服务器压力较大,这里我们来分析下如何减少服务端对堆栈信息的处理量。
在出现卡顿的情况下,我们采集到了多个堆栈,大概率的情况下,可能会存在多个重复的堆栈,而这个重复的堆栈信息才是我们应该关注的地方。我们可以对一个卡顿下的堆栈进行能hash排重,找出重复的堆栈。这样,服务器需要处理的数据量就会大大减少,同时也过滤出了我们需要重点关注的对象。对于开发人员来说,就能更快地找到卡顿的原因。
4、小结
在本节中,我们学习了自动化卡顿检测的原理,然后,我们使用这种方案进行了实战,最后,我还介绍了这种方案的问题和它的优化思路。
三、总结
在本篇文章中,我们主要对卡顿优化分析方法与工具 、自动化卡顿检测方案及优化相关的知识进行了全面且深入地讲解,这里再简单总结一下本篇文章涉及的两大主题:
- 1、卡顿优化分析方法与工具:背景介绍、卡顿分析方法之使用shell命令分析CPU耗时、卡顿优化工具。
- 2、自动化卡顿检测方案及优化:卡顿检测方案原理、AndroidPerformanceMonitor实战及其优化。
卡顿时间过长,一定会造成应用发生ANR。下面,我们就来从应用的ANR分析与实战来开始今天的探索之旅。
一、ANR分析与实战
1、ANR介绍与实战
首先,我们再来回顾一下ANR的几种常见的类型,如下所示:
- 1、KeyDispatchTimeout:按键事件在5s的时间内没有处理完成。
- 2、BroadcastTimeout:广播接收器在前台10s,后台60s的时间内没有响应完成。
- 3、ServiceTimeout:服务在前台20s,后台200s的时间内没有处理完成。
具体的时间定义我们可以在AMS(ActivityManagerService)中找到:
1 | // How long we allow a receiver to run before giving up on it. |
接下来,我们来看一下ANR的执行流程。
ANR执行流程
- 1、首先,我们的应用发生了ANR。
- 2、然后,我们的进程就会接收到异常终止信息,并开始写入进程ANR信息,也就是当时应用的场景信息,它包含了应用所有的堆栈信息、CPU、IO等使用的情况。
- 3、最后,会弹出一个ANR提示框,看你是要选择继续等待还是退出应用,需要注意这个ANR提示框不一定会弹出,根据不同ROM,它的表现情况也不同。因为有些手机厂商它会默认去掉这个提示框,以避免带来不好的用户体验。
分析完ANR的执行流程之后,我们来分析下怎样去解决ANR,究竟哪里可以作为我们的一个突破点。
在上面我们说过,当应用发生ANR时,会写入当时发生ANR的场景信息到文件中,那么,我们可不可以通过这个文件来判断是否发生了ANR呢?
关于根据ANR log进行ANR问题的排查与解决的方式笔者已经在深入探索Android稳定性优化的第三节ANR优化中讲解过了,这里就不多赘述了。
线上ANR监控方式
在深入探索Android稳定性优化的第三节ANR优化中我说到了使用FileObserver可以监听 /data/anr/traces.txt的变化,利用它可以实现线上ANR的监控,但是它有一个致命的缺点,就是高版本ROM需要root权限,解决方案是只能通过海外Google Play服务、国内Hardcoder的方式去规避。但是,这在国内显然是不现实的,那么,有没有更好的实现方式呢?
那就是ANR-WatchDog,下面我就来详细地介绍一下它。
ANR-WatchDog是一种非侵入式的ANR监控组件,可以用于线上ANR的监控,接下来,我们就使用ANR-WatchDog来监控ANR。
首先,在我们项目的app/build.gradle中添加如下依赖:
1 | implementation 'com.github.anrwatchdog:anrwatchdog:1.4.0' |
然后,在应用的Application的onCreate方法中添加如下代码启动ANR-WatchDog:
1 | new ANRWatchDog().start(); |
可以看到,它的初始化方式非常地简单,同时,它内部的实现也非常简单,整个库只有两个类,一个是ANRWatchDog,另一个是ANRError。
接下来我们来看一下ANRWatchDog的实现方式。
1 | /** |
可以看到,ANRWatchDog实际上是继承了Thread类,也就是它是一个线程,对于线程来说,最重要的就是其run方法,如下所示:
1 | private static final int DEFAULT_ANR_TIMEOUT = 5000; |
首先,在注释1处,我们将线程命名为了|ANR-WatchDog|。接着,在注释2处,声明了一个默认的超时间隔时间,默认的值为5000ms。然后,注释3处,在while循环中通过_uiHandler去post一个_ticker Runnable。注意这里的_tick默认是0,所以needPost即为true。接下来,线程会sleep一段时间,默认值为5000ms。在注释4处,如果主线程没有处理Runnable,即_tick的值没有被赋值为0,则说明发生了ANR,第二个_reported标志位是为了避免重复报道已经处理过的ANR。如果发生了ANR,就会调用接下来的代码,开始会处理debug的情况,然后,我们看到注释5处,如果没有主动给ANR_Watchdog设置线程名,则会默认会使用ANRError的NewMainOnly方法去处理ANR。ANRError的NewMainOnly方法如下所示:
1 | /** |
可以看到,在注释1处,首先获了主线程的堆栈信息,然后返回了一个包含主线程名、主线程堆栈信息以及发生ANR的最小时间值的实例。(我们可以改造其源码在此时添加更多的卡顿现场信息,如CPU 使用率和调度信息、内存相关信息、I/O 和网络相关的信息等等)
接下来,我们再回到ANRWatchDog的run方法中的注释6处,最后这里会通过ANRListener调用它的onAppNotResponding方法,其默认的处理会直接抛出当前的ANRError,导致程序崩溃。对应的代码如下所示:
1 | private static final ANRListener DEFAULT_ANR_LISTENER = new ANRListener() { |
了解了ANRWatchDog的实现原理之后,我们试一试它的效果如何。首先,我们给MainActivity中的悬浮按钮添加主线程休眠10s的代码,如下所示:
1 |
|
然后,我们重新安装运行项目,点击悬浮按钮,发现在10s内都不能触发屏幕点击和触摸事件,并且在10s之后,应用直接发生了崩溃。接着,我们在Logcat过滤栏中输入fatal关键字,找出致命的错误,log如下所示:
1 | 2020-01-18 09:55:53.459 29924-29969/? E/AndroidRuntime: FATAL EXCEPTION: |ANR-WatchDog| |
可以看到,发生崩溃的线程正是|ANR-WatchDog|。我们重点关注注释1,这里发生崩溃的位置是在MainActivity的onClick方法,对应的行数为170行,从前可知,这里正是线程休眠的地方。
接下来,我们来分析一下ANR-WatchDog的实现原理。
2、ANR-WatchDog原理
- 首先,我们调用了ANR-WatchDog的start方法,然后这个线程就会开始工作。
- 然后,我们通过主线程的Handler post一个消息将主线程的某个值进行一个加值的操作。
- post完成之后呢,我们这个线程就sleep一段时间。
- 在sleep之后呢,它就会来检测我们这个值有没有被修改,如果这个值被修改了,那就说明我们在主线程中执行了这个message,即表明主线程没有发生卡顿,否则,则说明主线程发生了卡顿。
- 最后,ANR-WatchDog就会判断发生了ANR,抛出一个异常给我们。
最后,ANR-WatchDog的工作流程简图如下所示:

上面我们最后说到,如果检测到主线程发生了卡顿,则会抛出一个ANR异常,这将会导致应用崩溃,显然不能将这种方案带到线上,那么,有什么方式能够自定义最后发生卡顿时的处理过程吗?
其实ANR-WatchDog自身就实现了一个我们自身也可以去实现的ANRListener,通过它,我们就可以对ANR事件去做一个自定义的处理,比如将堆栈信息压缩后保存到本地,并在适当的时间上传到APM后台。
3、小结
ANR-WatchDog是一种非侵入式的ANR监控方案,它能够弥补我们在高版本中没有权限去读取traces.txt文件的问题,需要注意的是,在线上这两种方案我们需要结合使用。
在之前,我们还讲到了AndroidPerformanceMonitor,那么它和ANR-WatchDog有什么区别呢?
对于AndroidPerformanceMonitor来说,它是监控我们主线程中每一个message的执行,它会在主线程的每一个message的前后打印一个时间戳,然后,我们就可以据此计算每一个message的具体执行时间,但是我们需要注意的是一个message的执行时间通常是非常短暂的,也就是很难达到ANR这个级别。然后我们来看看ANR-WatchDog的原理,它是不管应用是如何执行的,它只会看最终的结果,即sleep 5s之后,我就看主线程的这个值有没有被更改。如果说被改过,就说明没有发生ANR,否则,就表明发生了ANR。
根据这两个库的原理,我们便可以判断出它们分别的适用场景,对于AndroidPerformanceMonitor来说,它适合监控卡顿,因为每一个message它执行的时间并不长。对于ANR-WatchDog来说,它更加适合于ANR监控的补充。
此外,虽然ANR-WatchDog解决了在高版本系统没有权限读取 /data/anr/traces.txt 文件的问题,但是在Java层去获取所有线程堆栈以及各种信息非常耗时,对于卡顿场景不一定合适,它可能会进一步加剧用户的卡顿。如果是对性能要求比较高的应用,可以通过Hook Native层的方式去获得所有线程的堆栈信息,具体为如下两个步骤:
- 通过libart.so、dlsym调用ThreadList::ForEach方法,拿到所有的 Native 线程对象。
- 遍历线程对象列表,调用Thread::DumpState方法。
通过这种方式就大致模拟了系统打印 ANR 日志的流程,但是由于采用的是Hook方式,所以可能会产生一些异常甚至崩溃的情况,这个时候就需要通过 fork 子进程方式去避免这种问题,而且使用 子进程去获取堆栈信息的方式可以做到完全不卡住我们主进程。
但是需要注意的是,fork 进程会导致进程号发生改变,此时需要通过指定 /proc/[父进程 id]的方式重新获取应用主进程的堆栈信息。
通过 Native Hook 的 方式我们实现了一套“无损”获取所有 Java 线程堆栈与详细信息的卡顿监控体系。为了降低上报数据量,建议只有主线程的 Java 线程状态是 WAITING、TIME_WAITING 或者 BLOCKED 的时候,才去使用这套方案。
二、卡顿单点问题检测方案
除了自动化的卡顿与ANR监控之外,我们还需要进行卡顿单点问题的检测,因为上述两种检测方案的并不能满足所有场景的检测要求,这里我举一个小栗子:
1 | 比如我有很多的message要执行,但是每一个message的执行时间 |
除此之外,为了建立体系化的监控解决方案,我们就必须在上线之前将问题尽可能地暴露出来。
1、IPC单点问题检测方案
常见的单点问题有主线程IPC、DB操作等等,这里我就拿主线程IPC来说,因为IPC其实是一个很耗时的操作,但是在实际开发过程中,我们可能对IPC操作没有足够的重视,所以,我们经常在主程序中去做频繁IPC操作,所以说,这种耗时它可能并不到你设定卡顿的一个阈值,接下来,我们看一下,对于IPC问题,我们应该去监测哪些指标。
- 1、IPC调用类型:如PackageManager、TelephoneManager的调用。
- 2、每一个的调用次数与耗时。
- 3、IPC的调用堆栈(表明哪行代码调用的)、发生线程。
常规方案
常规方案就是在IPC的前后加上埋点。但是,这种方式不够优雅,而且,在平常开发过程中我们经常忘记某个埋点的真正用处,同时它的维护成本也非常大。
接下来,我们讲解一下IPC问题监测的技巧。
IPC问题监测技巧
在线下,我们可以通过adb命令的方式来进行监测,如下所示:
1 | // 1、首先,对IPC操作开始进行监控 |
然后,这里我们介绍一种优雅的实现方案,看过深入探索Android布局优化(上)的同学可能知道这里的实现方案无非就是ARTHook或AspectJ这两种方案,这里我们需要去监控IPC操作,那么,我们应该选用哪种方式会更好一些呢?(利用epic实现ARTHook)
要回答这个问题,就需要我们对ARTHook和AspectJ这两者的思想有足够的认识,对应ARTHook来说,其实我们可以用它来去Hook系统的一些方法,因为对于系统代码来说,我们无法对它进行更改,但是我们可以Hook住它的一个方法,在它的方法体里面去加上自己的一些代码。但是,对于AspectJ来说,它只能针对于那些非系统方法,也就是我们App自己的源码,或者是我们所引用到的一些jar、aar包。因为AspectJ实际上是往我们的具体方法里面插入相对应的代码,所以说,他不能够针对于我们的系统方法去做操作,在这里,我们就需要采用ARTHook的方式去进行IPC操作的监控。
在使用ARTHook去监控IPC操作之前,我们首先思考一下,哪些操作是IPC操作呢?
比如说,我们通过PackageManager去拿到我们应用的一些信息,或者去拿到设备的DeviceId这样的信息以及AMS相关的信息等等,这些其实都涉及到了IPC的操作,而这些操作都会通过固定的方式进行IPC,并最终会调用到android.os.BinderProxy,接下来,我们来看看它的transact方法,如下所示:
1 | public boolean transact(int code, Parcel data, Parcel reply, int flags) throws RemoteException { |
这里我们仅仅关注transact方法的参数即可,第一个参数是一个行动编码,为int类型,它是在FIRST_CALL_TRANSACTION与LAST_CALL_TRANSACTION之间的某个值,第二、三个参数都是Parcel类型的参数,用于获取和回复相应的数据,第四个参数为一个int类型的标记值,为0表示一个正常的IPC调用,否则表明是一个单向的IPC调用。然后,我们在项目中的Application的onCreate方法中使用ARTHook对android.os.BinderProxy类的transact方法进行Hook,代码如下所示:
1 | try { |
重新安装应用,即可看到如下的Log信息:
1 | 2020-01-22 19:52:47.657 10683-10683/json.chao.com.wanandroid I/WanAndroid-LOG: │ WanAndroidApp$1.beforeHookedMethod (WanAndroidApp.java:160) |
可以看出,这里弹出了应用中某一个IPC调用的所有堆栈信息。在这里,具体是在AbstractSimpleActivity的onCreate方法中调用了ServiceManager的getService方法,它是一个IPC调用的方法。这样,应用的IPC调用我们就能很方便地捕获到了。
大家可以看到,通过这种方式我们可以很方便地拿到应用中所有的IPC操作,并可以获得到IPC调用的类型、调用耗时、发生次数、调用的堆栈等等一系列信息。当然,除了IPC调用的问题之外,还有IO、DB、View绘制等一系列单点问题需要去建立与之对应的检测方案。
2、卡顿问题检测方案
对于卡顿问题检测方案的建设,主要是利用ARTHook去完善线下的检测工具,尽可能地去Hook相对应的操作,以暴露、分析问题。这样,才能更好地实现卡顿的体系化解决方案。
三、如何实现界面秒开?
界面的打开速度对用户体验来说是至关重要的,那么如何实现界面秒开呢?
其实界面秒开就是一个小的启动优化,其优化的思想可以借鉴启动速度优化与布局优化的一些实现思路。
1、界面秒开实现
首先,我们可以通过Systrace来观察CPU的运行状况,比如有没有跑满CPU;然后,我们在启动优化中学习到的优雅异步以及优雅延迟初始化等等一些方案;其次,针对于我们的界面布局,我们可以使用异步Inflate、X2C、其它的绘制优化措施等等;最后,我们可以使用预加载的方式去提前获取页面的数据,以避免网络或磁盘IO速度的影响,或者也可以将获取数据的方法放到onCreate方法的第一行。
那么我们如何去衡量界面的打开速度呢?
通常,我们是通过界面秒开率去统计页面的打开速度的,具体就是计算onCreate到onWindowFocusChanged的时间。当然,在某些特定的场景下,把onWindowFocusChanged作为页面打开的结束点并不是特别的精确,那我们可以去实现一个特定的接口来适配我们的Activity或Fragment,我们可以把那个接口方法作为页面打开的结束点。
那么,除了以上说到的一些界面秒开的实现方式之外,还没有更好的方式呢?
那就是Lancet。
2、Lancet
Lancet是一个轻量级的Android AOP框架,它具有如下优势:
- 1、编译速度快,支持增量编译。
- 2、API简单,没有任何多余代码插入apk。(这一点对应包体积优化时至关重要的)
然后,我来简单地讲解下Lancet的用法。Lancet自身提供了一些注解用于Hook,如下所示:
- @Prxoy:通常是用于对系统API调用的Hook。
- @Insert:经常用于操作App或者是Library当中的一些类。
接下来,我们就是使用Lancet来进行一下实战演练。
首先,我们需要在项目根目录的 build.gradle 添加如下依赖:
1 | dependencies{ |
然后,在 app 目录的’build.gradle’ 添加:
1 | apply plugin: 'me.ele.lancet' |
接下来,我们就可以使用Lancet了,这里我们需要先新建一个类去进行专门的Hook操作,如下所示:
1 | public class ActivityHooker { |
上述的方法就是对android.util.Log的i方法进行Hook,并在所有的msg后面加上”JsonChao”字符串,注意这里的i方法我们需要从android.util.Log里面将它的i方法复制过来,确保方法名和对应的参数信息一致;然后,方法上面的@TargetClass与@Proxy分别是指定对应的全路径类名与方法名;最后,我们需要通过Lancet提供的Origin类去调用它的call方法来实现返回原来的调用信息。完成之后,我们重新运行项目,会出现如下log信息:
1 | 2020-01-23 13:13:34.124 7277-7277/json.chao.com.wanandroid I/MultiDex: VM with version 2.1.0 has multidex supportJsonChao |
可以看到,log后面都加上了我们预先添加的字符串,说明Hook成功了。下面,我们就可以用Lancet来统计一下项目界面的秒开率了,代码如下所示:
1 | public static ActivityRecord sActivityRecord; |
上面,我们通过@TargetClass和@Insert两个注解实现Hook了android.support.v7.app.AppCompatActivity的onCreate与onWindowFocusChanged方法。我们注意到,这里@Insert注解可以指定两个参数,其源码如下所示:
1 |
|
第二个参数mayCreateSuper设定为true则表明如果没有重写父类的方法,则会默认去重写这个方法。对应到我们ActivityHooker里面实现的@Insert注解方法就是如果当前的Activity没有重写父类的onCreate和 onWindowFocusChanged方法,则此时默认会去重写父类的这个方法,以避免因某些Activity不存在该方法而Hook失败的情况。
然后,我们注意到@TargetClass也可以指定两个参数,其源码如下所示:
1 |
|
第二个参数scope指定的值是一个枚举,可选的值如下所示:
1 | public enum Scope { |
对于Scope.SELF,它代表仅匹配目标value所指定的一个匹配类;对于DIRECT,它代表匹配value所指定的类的一个直接子类;如果是Scope.ALL,它就表明会去匹配value所指定的类的所有子类,而我们上面指定的value值为android.support.v7.app.AppCompatActivity,因为scope指定为了Scope.ALL,则说明会去匹配AppCompatActivity的所有子类。而最后的Scope.LEAF 代表匹配 value 指定类的最终子类,因为java是单继承,所以继承关系是树形结构,所以这里代表了指定类为顶点的继承树的所有叶子节点。
最后,我们设定了一个ActivityRecord类去记录onCreate与onWindowFocusChanged的时间戳,如下所示:
1 | public class ActivityRecord { |
通过sActivityRecord.mOnWindowsFocusChangedTime - sActivityRecord.mOnCreateTime得到的时间即为界面的打开速度,最后,重新运行项目,会得到如下log信息:
1 | 2020-01-23 14:12:16.406 15098-15098/json.chao.com.wanandroid I/WanAndroid-LOG: │ [null | 57 | json_chao_com_wanandroid_aop_ActivityHooker_onWindowFocusChanged] json.chao.com.wanandroid.ui.main.activity.SplashActivity onWindowFocusChanged cost 257 |
从上面的log信息,我们就可以知道 SplashActivity 和 MainActivity 的界面打开速度分别是257ms和608ms。
最后,我们来看下界面秒开的监控纬度。
3、界面秒开监控纬度
对于界面秒开的监控纬度,主要分为以下三个方面:
- 总体耗时
- 生命周期耗时
- 生命周期间隔耗时
首先,我们会监控界面打开的整体耗时,也就是onCreate到onWindowFocusChanged这个方法的耗时;当然,如果我们是在一个特殊的界面,我们需要更精确的知道界面打开的一个时间,这个我们可以用自定义的接口去实现。其次,我们也需要去监控生命周期的一个耗时,如onCreate、onStart、onResume等等。最后,我们也需要去做生命周期间隔的耗时监控,这点经常被我们所忽略,比如onCreate的结束到onStart开始的这一段时间,也是有时间损耗的,我们可以监控它是不是在一个合理的范围之内。通过这三个方面的监控纬度,我们就能够非常细粒度地去检测页面秒开各个方面的情况。
四、优雅监控耗时盲区
尽管我们在应用中监控了很多的耗时区间,但是还是有一些耗时区间我们还没有捕捉到,如onResume到列表展示的间隔时间,这些时间在我们的统计过程中很容易被忽视,这里我们举一个小栗子:
1 | 我们在Activity的生命周期中post了一个message,那这个message很可能其中 |
其实这种场景非常常见,接下来,我们就在项目中来进行实战演练。
首先,我们在MainActivity的onCreate中加上post消息的一段代码,其中模拟了延迟1000ms的耗时操作,代码如下所示:
1 | // 以下代码是为了演示Msg导致的主线程卡顿 |
接着,我们在RecyclerView对应的Adapter中将列表展示的时间打印出来,如下所示:
1 | if (helper.getLayoutPosition() == 1 && !mHasRecorded) { |
最后,我们重新运行下项目,看看两者的执行时间,log信息如下:
1 | 2020-01-23 15:21:55.076 19091-19091/json.chao.com.wanandroid I/WanAndroid-LOG: │ [MainActivity.java | 108 | lambda$initEventAndData$1$MainActivity] Msg 执行 |
从log信息中可以看到,MAinActivity的onWindowFocusChanged方法延迟了1000ms才被调用,与此同时,列表页时延迟了1000ms才展示出来。也就是说,post的这个message消息是执行在界面、列表展示之前的。因为任何一个开发都有可能在某一个生命周期或者是某一个阶段以及一些第三方的SDK里面,回去做一些handler post的相关操作,这样,他的handler post的message的执行,很有可能在我们的界面或列表展示之前就被执行,所以说,出现这种耗时的盲区是非常普遍的,而且也不好排查,下面,我们分析下耗时盲区存在的难点。
1、耗时盲区监控难点
首先,我们可以通过细化监控的方式去获取耗时的一些盲区,但是我们却不知道在这个盲区中它执行了什么操作。其次,对于线上的一些耗时盲区,我们是无法进行排查的。
这里,我们先来看看如何建立耗时盲区监控的线下方案。
2、耗时盲区监控线下方案
这里我们直接使用TraceView去检测即可,因为它能够清晰地记录线程在具体的时间内到底做了什么操作,特别适合一段时间内的盲区监控。
然后,我们来看下如何建立耗时盲区监控的线上方案。
3、耗时盲区监控线上方案
我们知道主线程的所有方法都是通过message来执行的,还记得在之前我们学习了一个库:AndroidPerformanceMonitor,我们是否可以通过这个mLogging来做盲区检测呢?通过这个mLogging确实可以知道我们主线程发生的message,但是通过mLogging无法获取具体的调用栈信息,因为它所获取的调用栈信息都是系统回调回来的,它并不知道当前的message是被谁抛出来的,所以说,这个方案并不够完美。
那么,我们是否可以通过AOP的方式去切Handler方法呢?比如sendMessage、sendMessageDeleayd方法等等,这样我们就可以知道发生message的一个堆栈,但是这种方案也存在着一个问题,就是它不清楚准确的执行时间,我们切了这个handler的方法,仅仅只知道它具体是在哪个地方被发的和它所对应的堆栈信息,但是无法获取准确的执行时间。如果我们想知道在onResume到列表展示之间执行了哪些message,那么通过AOP的方式也无法实现。
那么,最终的耗时盲区监控的一个线上方案就是使用一个统一的Handler,定制了它的两个方法,一个是sendMessageAtTime,另外一个是dispatchMessage方法。因为对于发送message,不管调用哪个方法最终都会调用到一个是sendMessageAtTime这个方法,而处理message呢,它最终会调用dispatchMessage方法。然后,我们需要定制一个gradle插件,来实现自动化的接入我们定制好的handler,通过这种方式,我们就能在编译期间去动态地替换所有使用Handler的父类为我们定制好的这个handler。这样,在整个项目中,所有的sendMessage和handleMessage都会经过我们的回调方法。接下来,我们来进行一下实战演练。
首先,我这里给出定制好的全局Handler类,如下所示:
1 | public class GlobalHandler extends Handler { |
上面的GlobalHandler将会是我们项目中所有Handler的一个父类。在注释1处,我们在sendMessageAtTime这个方法里面判断如果message发送成功,将会把当前message对象对应的调用栈信息都保存到一个ConcurrentHashMap中,GetDetailHandlerHelper类的代码如下所示:
1 | public class GetDetailHandlerHelper { |
这样,我们就能够知道这个message它是被谁发送过来的。然后,在dispatchMessage方法里面,我们可以计算拿到其处理消息的一个耗时,并在注释2处将这个耗时保存到一个jsonObject对象中,同时,我们也可以通过GetDetailHandlerHelper类的ConcurrentHashMap对象拿到这个message对应的堆栈信息,并在注释3处将它们输出到log控制台上。当然,如果是线上监控,则会把这些信息保存到本地,然后选择合适的时间去上传。最后,我们还可以在方法体里面做一个判断,我们设置一个阈值,比如阈值为20ms,超过了20ms就把这些保存好的信息上报到APM后台。
在前面的实战演练中,我们使用了handler post的方式去发送一个消息,通过gradle插件将所有handler的父类替换为我们定制好的GlobalHandler之后,我们就可以优雅地去监控应用中的耗时盲区了。
对于实现全局替换handler的gradle插件,除了使用AspectJ实现之外,这里推荐一个已有的项目:DroidAssist。
然后,重新运行项目,关键的log信息如下所示:
1 | MsgDetail {"Msg_Cost":1001,"MsgTrace":"Handler (com.json.chao.com.wanandroid.performance.handler.GlobalHandler) {b0d4d48} \n\tat |
从以上信息我们不仅可以知道message执行的时间,还可以从对应的堆栈信息中得到发送message的位置,这里的位置是MainActivity的107行,也就是new Handler().post()这一行代码。使用这种方式我们就可以知道在列表展示之前到底执行了哪些自定义的message,我们一眼就可以知道哪些message其实是不符合我们预期的,比如说message的执行时间过长,或者说这个message其实可以延后执行,这个我们都可以根据实际的项目和业务需求进行相应地修改。
4、耗时盲区监控方案总结
耗时盲区监控是我们卡顿监控中不可或缺的一个环节,也是卡顿监控全面性的一个重要保障。而需要注意的是,TraceView仅仅适用于线下的一个场景,同时对于TraceView来说,它可以用于监控我们系统的message。而最后介绍的动态替换的方式其实是适合于线上的,同时,它仅仅监控应用自身的一个message。
五、卡顿优化技巧总结
1、卡顿优化实践经验
如果应用出现了卡顿现象,那么可以考虑以下方式进行优化:
- 首先,对于耗时的操作,我们可以考虑异步或延迟初始化的方式,这样可以解决大多数的问题。但是,大家一定要注意代码的优雅性。
- 对于布局加载优化,可以采用AsyncLayoutInflater或者是X2C的方式来优化主线程IO以及反射导致的消耗,同时,需要注意,对于重绘问题,要给与一定的重视。
- 此外,内存问题也可能会导致应用界面的卡顿,我们可以通过降低内存占用的方式来减少GC的次数以及时间,而GC的次数和时间我们可以通过log查看。
然后,我们来看看卡顿优化的工具建设。
2、卡顿优化工具建设
工具建设这块经常容易被大家所忽视,但是它的收益却非常大,也是卡顿优化的一个重点。首先,对于系统工具而言,我们要有一个认识,同时一定要学会使用它,这里我们再回顾一下。
- 对于Systrace来说,我们可以很方便地看出来它的CPU使用情况。另外,它的开销也比较小。
- 对于TraceView来说,我们可以很方便地看出来每一个线程它在特定的时间内做了什么操作,但是TraceView它的开销相对比较大,有时候可能会被带偏优化方向。
- 同时,需要注意,StrictMode也是一个非常强大的工具。
然后,我们介绍了自动化工具建设以及优化方案。我们介绍了两个工具,AndroidPerformanceMonitor以及ANR-WatchDog。同时针对于AndroidPerformanceMonitor的问题,我们采用了高频采集,以找出重复率高的堆栈这样一种方式进行优化,在学习的过程中,我们不仅需要学会怎样去使用工具,更要去理解它们的实现原理以及各自的使用场景。
同时,我们对于卡顿优化工具的建设也做了细化,对于单点问题,比如说IPC监控,我们通过Hook的手段来做到尽早的发现问题。对于耗时盲区的监控,我们在线上采用的是替换Handler的方式来监控所有子线程message执行的耗时以及调用堆栈。
最后,我们来看一下卡顿监控的指标。我们会计算应用整体的卡顿率,ANR率、界面秒开率以及交换时间、生命周期时间等等。在上报ANR信息的同时,我们也需要上报环境和场景信息,这样不仅方便我们在不同版本之间进行横向对比,同时,也可以结合我们的报警平台在第一时间感知到异常。
六、常见卡顿问题解决方案总结
1、CPU资源争抢引发的卡顿问题如何解决?
此时,我们的应用不仅应该控制好核心功能的CPU消耗,也需要尽量减少非核心需求的CPU消耗。
2、要注意Android Java中提供的哪些低效的API?
比如List.removeall方法,它内部会遍历一次需要过滤的消息列表,在已经存在循环列表的情况下会造成CPU资源的冗余使用,此时应该去优化相关的算法,避免使用List.removeall这个方法。
3、如何减少图形处理的CPU消耗?
这个时候我们需要使用神器renderscript来图形处理的相关运算,将CPU转换到GPU。关于renderscript的背景知识可以看看笔者之前写的深入探索Android布局优化(下)。
4、硬件加速长中文字体渲染时造成的卡顿如何解决?
此时只能关闭文本TextView的硬件加速,如下所示:
1 | textView.setLayerType(View.LAYER_TYPE_SOFTWARE, null); |
当开启了硬件加速进行长中文字体的渲染时,首先会调用ViewRootImpl.draw()方法,最后会调用GLES20Canvas.nDrawDisplayList()方法开始通过JNI调整到Native层。在这个方法里,会继续调用OpenGLRenderer.drawDisplayList()方法,它通过调用DisplayList的replay方法,以回放前面录制的DisplayList执行绘制操作。
DisplayList的replay方法会遍历DisplayList中保存的每一个操作。其中渲染字体的操作名是DrawText,当遍历到一个DrawText操作时,会调用OpenGLRender::drawText方法区渲染字体。最终,会在OpenGLRender::drawText方法里去调用Font::render()方法渲染字体,而在这个方法中有一个很关键的操作,即获取字体缓存。我们都知道每一个中文的编码都是不同的,因此中文的缓存效果非常不理想,但是对于英文而言,只需要缓存26个字母就可以了。在Android 4.1.2版本之前对文本的Buffer设置过小,所以情况比较严重,如果你的应用在其它版本的渲染性能尚可,就可以仅仅把Android 4.0.x的硬件加速关闭,代码如下所示:
1 | // AndroidManifest中 |
此外,硬件渲染还有一些其它的问题在使用时需要注意,具体为如下所示:
- 1、在软件渲染的情况下,如果需要重绘某个父View的所有子View,只需要调用这个Parent View的invalidate()方法即可,但如果开启了硬件加速,这么做是行不通的,需要遍历整个子View并调用invalidate()。
- 2、在软件渲染的情况下,会常常使用Bitmap重用的方式来节省内存,但是如果开启了硬件加速,这将会无效。
- 3、当开启硬件加速的UI在前台运行时,需要耗费额外的内存。当硬件加速的UI切换到后台时,上述额外内存有可能不会释放,这大多存在于Android 4.1.2版本中。
- 4、长或宽大于2048像素的Bitmap无法绘制,显示为一片透明。原因是OpenGL的材质大小上限为2048 * 2048,因此对于超过2048像素的Bitmap,需要将其切割成2048 * 2048以内的图片块,最后在显示的时候拼起来。
- 5、当UI中存在过渡绘制时,可能会发生花屏,一般来说绘制少于5层不会出现花屏现象,如果有大块红色区域就要十分小心了。
- 6、需要注意,关于LAYER_TYPE_SOFTWARE,虽然无论在App打开硬件加速或没有打开硬件加速的时候,都会通过软件绘制Bitmap作为离屏缓存,但区别在于打开硬件加速的时候,Bitmap最终还会通过硬件加速方式drawDisplayList去渲染这个Bitmap。
七、卡顿优化的常见问题
1、你是怎么做卡顿优化的?
从项目的初期到壮大期,最后再到成熟期,每一个阶段都针对卡顿优化做了不同的处理。各个阶段所做的事情如下所示:
- 1、系统工具定位、解决
- 2、自动化卡顿方案及优化
- 3、线上监控及线下监测工具的建设
我做卡顿优化也是经历了一些阶段,最初我们的项目当中的一些模块出现了卡顿之后,我是通过系统工具进行了定位,我使用了Systrace,然后看了卡顿周期内的CPU状况,同时结合代码,对这个模块进行了重构,将部分代码进行了异步和延迟,在项目初期就是这样解决了问题。
但是呢,随着我们项目的扩大,线下卡顿的问题也越来越多,同时,在线上,也有卡顿的反馈,但是线上的反馈卡顿,我们在线下难以复现,于是我们开始寻找自动化的卡顿监测方案,其思路是来自于Android的消息处理机制,主线程执行任何代码都会回到Looper.loop方法当中,而这个方法中有一个mLogging对象,它会在每个message的执行前后都会被调用,我们就是利用这个前后处理的时机来做到的自动化监测方案的。同时,在这个阶段,我们也完善了线上ANR的上报,我们采取的方式就是监控ANR的信息,同时结合了ANR-WatchDog,作为高版本没有文件权限的一个补充方案。
在做完这个卡顿检测方案之后呢,我们还做了线上监控及线下检测工具的建设,最终实现了一整套完善,多维度的解决方案。
2、你是怎么样自动化的获取卡顿信息?
我们的思路是来自于Android的消息处理机制,主线程执行任何代码它都会走到Looper.loop方法当中,而这个函数当中有一个mLogging对象,它会在每个message处理前后都会被调用,而主线程发生了卡顿,那就一定会在dispatchMessage方法中执行了耗时的代码,那我们在这个message执行之前呢,我们可以在子线程当中去postDelayed一个任务,这个Delayed的时间就是我们设定的阈值,如果主线程的messaege在这个阈值之内完成了,那就取消掉这个子线程当中的任务,如果主线程的message在阈值之内没有被完成,那子线程当中的任务就会被执行,它会获取到当前主线程执行的一个堆栈,那我们就可以知道哪里发生了卡顿。
经过实践,我们发现这种方案获取的堆栈信息它不一定是准确的,因为获取到的堆栈信息它很可能是主线程最终执行的一个位置,而真正耗时的地方其实已经执行完成了,于是呢,我们就对这个方案做了一些优化,我们采取了高频采集的方案,也就是在一个周期内我们会多次采集主线程的堆栈信息,如果发生了卡顿,那我们就将这些卡顿信息压缩之后上报给APM后台,然后找出重复的堆栈信息,这些重复发生的堆栈大概率就是卡顿发生的一个位置,这样就提高了获取卡顿信息的一个准确性。
3、卡顿的一整套解决方案是怎么做的?
首先,针对卡顿,我们采用了线上、线下工具相结合的方式,线下工具我们需要尽可能早地去暴露问题,而针对于线上工具呢,我们侧重于监控的全面性、自动化以及异常感知的灵敏度。
同时呢,卡顿问题还有很多的难题。比如说有的代码呢,它不到你卡顿的一个阈值,但是执行过多,或者它错误地执行了很多次,它也会导致用户感官上的一个卡顿,所以我们在线下通过AOP的方式对常见的耗时代码进行了Hook,然后对一段时间内获取到的数据进行分析,我们就可以知道这些耗时的代码发生的时机和次数以及耗时情况。然后,看它是不是满足我们的一个预期,不满足预期的话,我们就可以直接到线下进行修改。同时,卡顿监控它还有很多容易被忽略的一个盲区,比如说生命周期的一个间隔,那对于这种特定的问题呢,我们就采用了编译时注解的方式修改了项目当中所有Handler的父类,对于其中的两个方法进行了监控,我们就可以知道主线程message的执行时间以及它们的调用堆栈。
对于线上卡顿,我们除了计算App的卡顿率、ANR率等常规指标之外呢,我们还计算了页面的秒开率、生命周期的执行时间等等。而且,在卡顿发生的时刻,我们也尽可能多地保存下来了当前的一个场景信息,这为我们之后解决或者复现这个卡顿留下了依据。
八、总结
恭喜你,如果你看到了这里,你会发现要做好应用的卡顿优化的确不是一件简单的事,它需要你有成体系的知识构建基底。最后,我们再来回顾一下面对卡顿优化,我们已经探索的以下九大主题:
- 1、卡顿优化分析方法与工具:背景介绍、卡顿分析方法之使用shell命令分析CPU耗时、卡顿优化工具。
- 2、自动化卡顿检测方案及优化:卡顿检测方案原理、AndroidPerformanceMonitor实战及其优化。
- 3、ANR分析与实战:ANR执行流程、线上ANR监控方式、ANR-WatchDog原理。
- 4、卡顿单点问题检测方案:IPC单点问题检测方案、卡顿问题检测方案。
- 5、如何实现界面秒开?:界面秒开实现、Lancet、界面秒开监控纬度。
- 6、优雅监控耗时盲区:耗时盲区监控难点以及线上与线下的监控方案。
- 7、卡顿优化技巧总结:卡顿优化实践经验、卡顿优化工具建设。
- 8︎、常见卡顿问题解决方案总结
- 9、卡顿优化的常见问题
相信看到这里,你一定收获满满,但是要记住,方案再好,也只有自己动手去实践,才能真正地掌握它。只有重视实践,充分运用感性认知潜能,在项目中磨炼自己,才是正确的学习之道。在实践中,在某些关键动作上刻意练习,也会取得事半功倍的效果。