HashMap(jdk1.8)

HashMap的工作原理
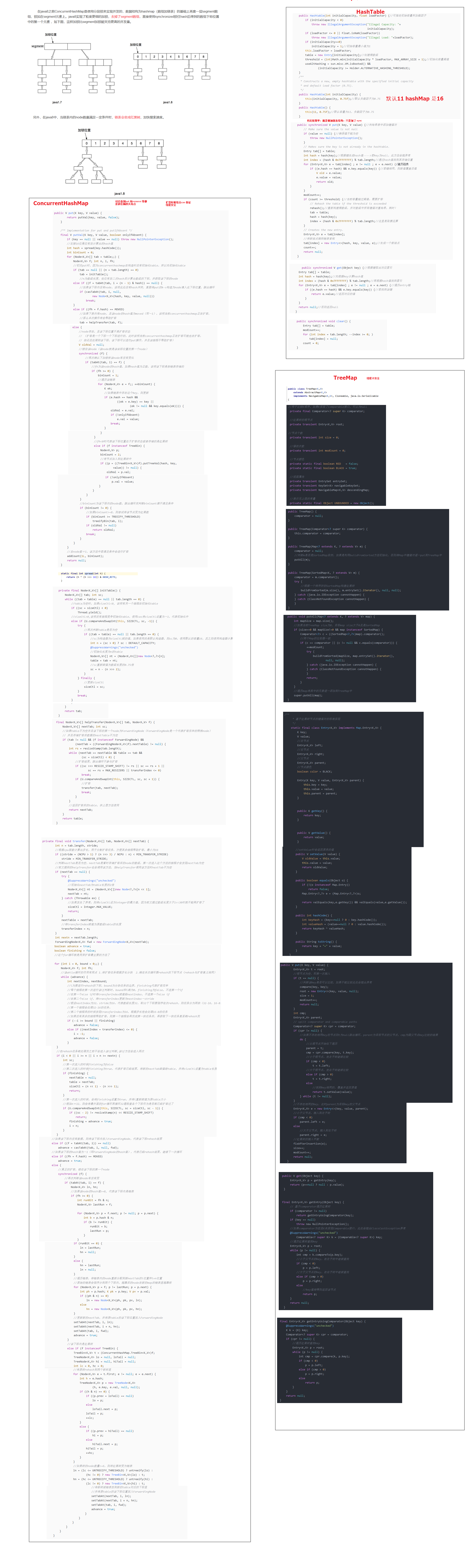
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来储存Entry对象。当两个对象的hashcode相同时,它们的bucket位置相同,‘碰撞’会发生。因为HashMap使用链表存储对象,这个Entry会存储在链表中,当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。
如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?
默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。
为什么String, Interger这样的wrapper类适合作为键?
因为String是不可变的,也是final的,而且已经重写了equals()和hashCode()方法了。其他的wrapper类也有这个特点。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。不可变性还有其他的优点如线程安全。如果你可以仅仅通过将某个field声明成final就能保证hashCode是不变的,那么请这么做吧。因为获取对象的时候要用到equals()和hashCode()方法,那么键对象正确的重写这两个方法是非常重要的。如果两个不相等的对象返回不同的hashcode的话,那么碰撞的几率就会小些,这样就能提高HashMap的性能。
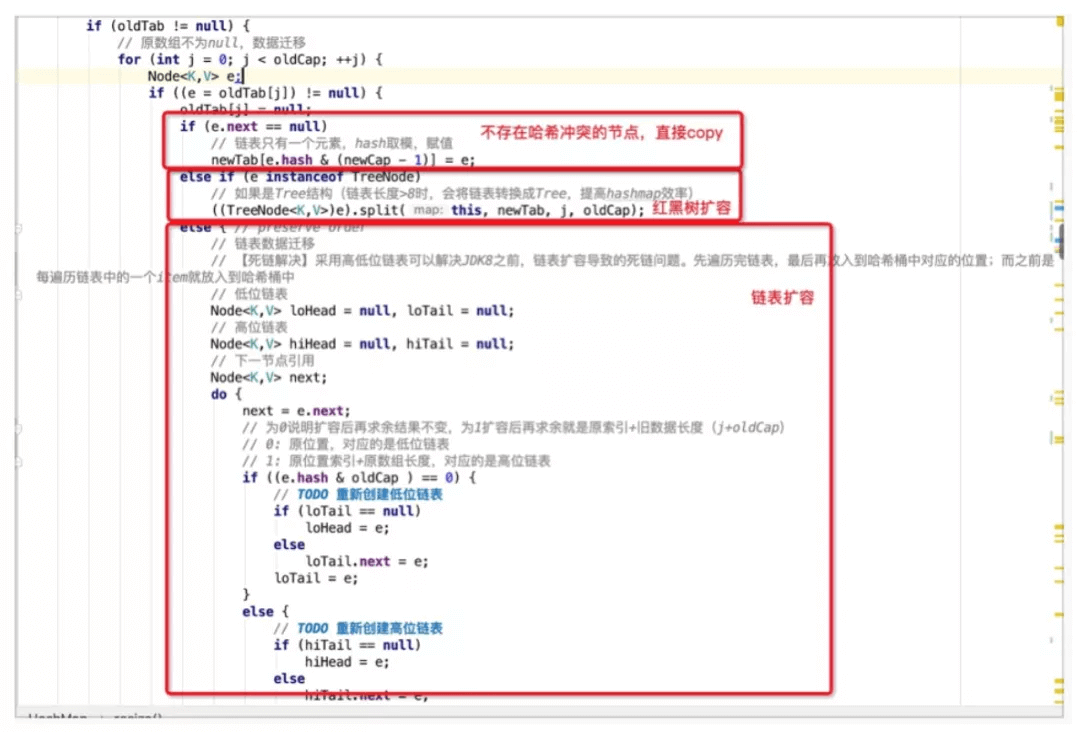
自动扩容
最小可用原则,容量超过一定阈值便自动进行扩容。
调用resize()来进行扩容。扩容是发生在putVal()后,即写入元素后才判断大小是否超过阈值threshold,如果超过则进行扩容(扩容1倍,通过<<1来实现)
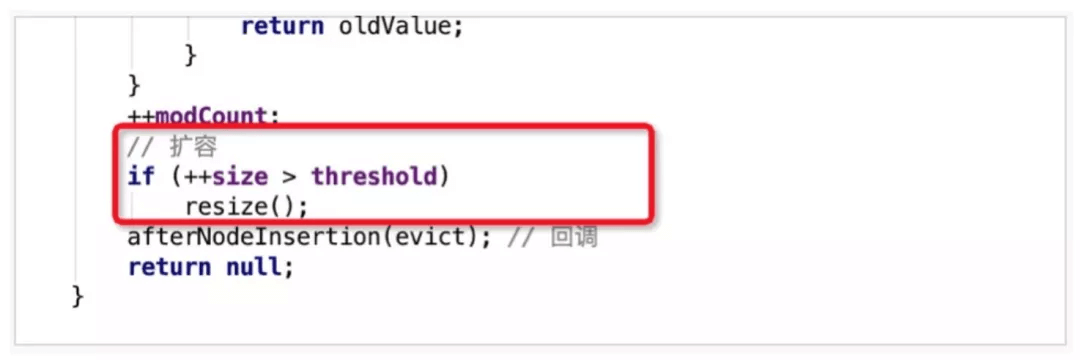
扩容1倍,通过<<1来实现,同时新的阈值newThr也扩容为老阈值的1倍
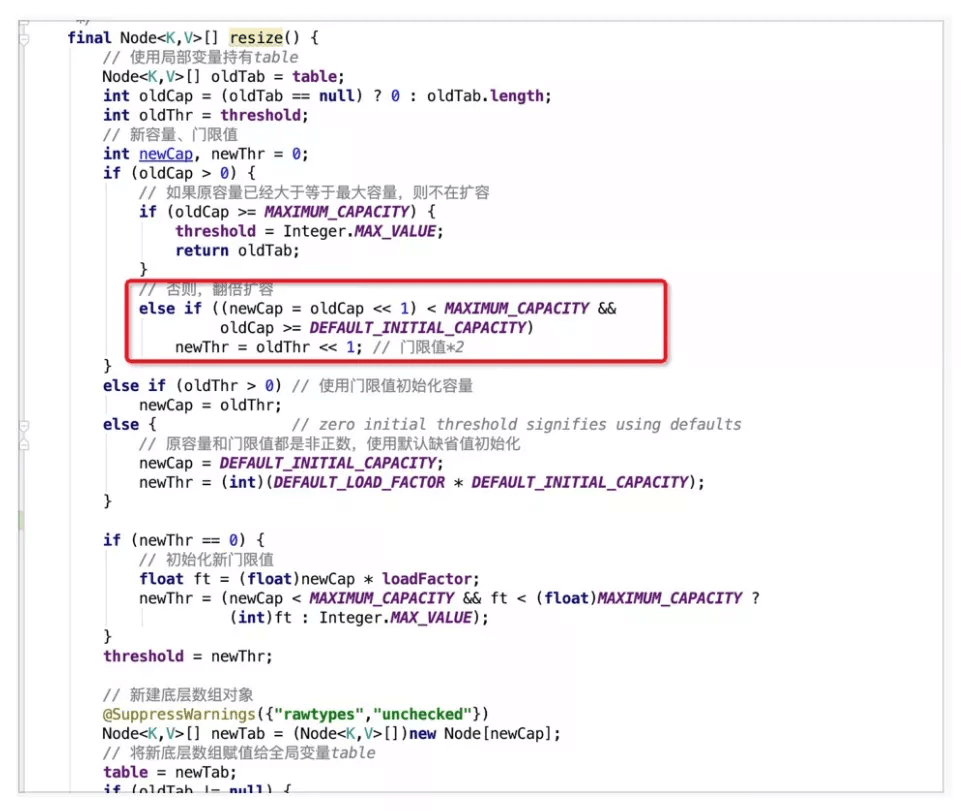
扩容时,总共存在三种情况:
- 哈希桶数组中某个位置只有1个元素,即不存在哈希冲突时,则直接将该元素copy至新哈希桶数组的对应位置即可。
- 哈希桶数组中某个位置的节点为树节点时,则执行红黑树的扩容操作。
- 哈希桶数组中某个位置的节点为普通节点时,则执行链表扩容操作,在JDK1.8中,为了避免之前版本中并发扩容所导致的死链问题,引入了高低位链表辅助进行扩容操作。
ArrayList、LinkedList、Vector

HashTable